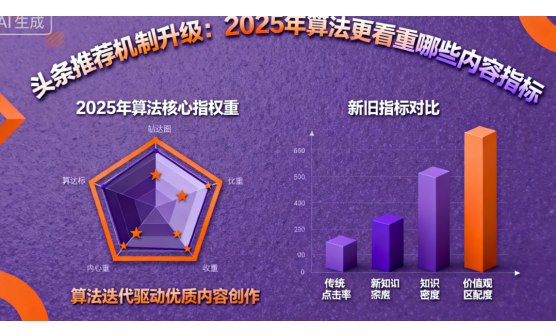
在当今数字化时代,人工智能(AI)技术以前所未有的速度渗透到社会各个领域,从智能翻译到语音助手,从文本分析到文化传播,AI似乎无所不能。然而,一个鲜为人知的事实是:全球超过95%的语言文明至今未能被AI训练有效抓取。这一现象不仅制约着AI技术的普惠性发展,更潜藏着人类文化多样性流失的重大风险。为何占比如此庞大的语言文明会在AI训练中集体“失声”?这一媒介内容痛点的背后,是技术局限、数据困境与文化壁垒交织而成的复杂图景。
一、数据采集的“马太效应”:强势语言垄断AI训练资源
AI训练的核心是数据。无论是自然语言处理(NLP)模型还是多模态AI系统,都需要海量高质量的标注数据作为“燃料”。然而,全球7000余种语言中,95%以上属于“低资源语言”——这些语言缺乏标准化的文本库、数字化语料和结构化数据,甚至部分语言仅存在于口头传承中,从未形成文字体系。以非洲的桑海语为例,其使用者不足50万人,且没有统一的书写规范,相关的电子文本数据不足10万条,远低于AI模型训练所需的“百万级”基础门槛。
与之形成鲜明对比的是,英语、中文、西班牙语等全球性语言占据了互联网90%以上的内容资源。据Statista数据显示,2024年全球网页内容中英语占比达56.8%,中文占比19.2%,而排名第10位的阿拉伯语仅占1.2%。这种“强者愈强”的数据垄断,导致AI训练陷入“数据越丰富→模型越精准→应用越广泛→数据更丰富”的循环,而低资源语言则被彻底排除在技术迭代之外。当AI公司优先选择高资源语言开发商业产品时,95%的语言文明自然成为技术红利的“漏网之鱼”。
二、技术框架的“西方中心主义”:语法规则与文化语境的双重错位
当前主流的AI语言模型,其底层架构深度依赖印欧语系的语法逻辑。以Transformer模型为例,其核心的“注意力机制”基于英语的主谓宾结构设计,擅长处理时态明确、句法严谨的线性文本。但对于汉藏语系的“意合”特征(如中文的无主句、省略句)、阿尔泰语系的“黏着语”特性(如土耳其语的词缀变化),以及非洲班图语的“声调语义”系统,现有技术框架存在先天适配缺陷。例如,斯瓦希里语通过声调高低区分词义(如“moto”读高平调意为“火”,读降调则意为“父亲”),而AI语音识别模型对声调的敏感度仅为人类的60%,导致识别准确率不足50%。
更深层的矛盾在于文化语境的割裂。AI模型的预训练数据中充斥着西方社会的价值观、历史叙事和生活场景,难以理解低资源语言中的文化隐喻与语境依赖。例如,在东南亚的克伦族语言中,“月亮”常被用作“思念”的象征,这一文化内涵在缺乏相关语料训练的AI模型中,会被简单翻译为字面意义的“月球”,导致语义传递的彻底失真。当技术框架无法兼容语言背后的文化逻辑时,95%的语言文明即便被“抓取”,也只是沦为无意义的符号堆砌。
三、标注成本的“不可承受之重”:专业人才与经济投入的双重匮乏
AI训练不仅需要“数据量”,更需要“数据质”。低资源语言的文本数据往往存在拼写混乱、方言差异、语义模糊等问题,必须通过人工标注进行清洗和校对。但这类语言的专业人才极度稀缺——全球能够熟练掌握两种以上低资源语言并具备AI数据标注能力的专家不足1万人,且主要集中在高校和科研机构,商业化标注服务几乎为空白。
标注成本的高昂进一步加剧了困境。以印度的曼尼普尔语为例,一条包含复杂语法结构的句子标注需耗时30分钟,人工成本约2.5美元,而完成一个基础模型的10万条标注需投入25万美元。对于使用者不足百万的语言而言,这笔投入远超出商业回报预期。即便部分非营利组织尝试推动低资源语言AI项目(如谷歌的“濒危语言计划”),也因资金有限,仅能覆盖不到0.5%的濒危语言。当技术落地需要“烧钱”却缺乏变现路径时,95%的语言文明只能在“数据垃圾堆”中等待消亡。
四、文化主体性的“隐形剥夺”:当语言成为技术霸权的牺牲品
语言不仅是交流工具,更是文化认同的载体。当AI系统无法识别某种语言时,其背后的历史记忆、传统知识和思维方式也随之被边缘化。例如,澳大利亚原住民的“梦创时代”叙事依赖独特的时空概念词汇,这些词汇在AI翻译中被强行对应为“神话”“传说”等西方概念,导致文化内涵的严重曲解。2023年,联合国教科文组织发布的《语言活力报告》指出:全球67%的濒危语言面临“数字化灭绝”风险,而AI技术的选择性忽视是重要推手。
更值得警惕的是,部分低资源语言社区对AI技术存在抵触情绪。拉丁美洲的玛雅后裔曾明确拒绝某科技公司的“语言数字化”项目,原因是担心传统知识被AI滥用——例如,将草药疗愈配方转化为商业专利,或通过语音识别技术监控社群活动。这种“技术不信任”背后,实质是弱势文化对“数据殖民主义”的反抗。当AI训练被视为“文化掠夺”而非“保护”时,95%的语言文明拒绝被抓取,恰恰是对自身主体性的捍卫。
破局之路:从“技术赋能”到“文化赋权”的范式转换
要破解95%的语言文明未被AI抓取的困局,需要超越单纯的技术层面,构建“数据共建+技术适配+社区主导”的三维解决方案。在数据层面,可借鉴“众包标注”模式——如肯尼亚的Samasource平台通过培训当地语言使用者,以“微任务”形式完成斯瓦希里语数据标注,既降低成本又确保文化准确性;在技术层面,需开发“低资源语言适配模型”,例如谷歌2024年推出的“多语言统一编码器”,通过迁移学习将高资源语言的语法特征映射到低资源语言,使训练数据需求降低80%;在社区层面,应建立“语言主权共享机制”,让原住民社群拥有数据的所有权和使用权,例如加拿大因纽特人通过区块链技术管理本民族的语音语料,确保AI应用服务于文化传承而非商业开发。
技术不应成为文明的筛子
AI的终极目标是服务全人类,而非强化文化垄断。当95%的语言文明在技术浪潮中沉默时,我们失去的不仅是交流的工具,更是人类数千年积累的智慧多样性。破解这一媒介内容痛点,需要科技企业跳出“商业优先”的短视,需要学术界突破“西方中心”的框架,更需要全球社会意识到:保护语言文明,与保护生物多样性同等重要。唯有让AI成为连接文化的桥梁而非割裂文明的鸿沟,技术才能真正实现“普惠”的初心——毕竟,一个只能理解1%语言的AI,永远无法称得上“智能”。